The Role of Redundancy in Building Resilient Industrial Networks
In industrial environments, network downtime frequently results in costly delays, production losses, and even potential danger to employees. That's why resiliency is crucial in industrial Ethernet switching, because it enables networks to withstand failures, faults, and disturbances that lead to downtime.
In this blog post, we will explore the importance of network resilience in industrial Ethernet switching and discuss some of the key strategies and technologies for achieving it, including how to implement network redundancy mechanisms and the Spanning Tree Protocol (STP).
Understanding Network Resilience
Network resilience: what is it? Resilience refers to the capacity of a network to withstand disturbances so it can continue offering services at an acceptable level. Resilient networks are essential for the efficient administration, oversight, and operation of factory infrastructures and critical processes.
Maintaining a resilient and reliable network with high availability across many network devices in the best of operating conditions is difficult enough, but there are additional challenges in industrial environments. These would include the threat of extremely high temperatures, electrical interference, unplanned network outages, and unforgiving physical surroundings that can compromise network performance and dependability.
According to estimates from Gartner, the average manufacturing company loses over $300,000 for each hour of downtime. Other research suggests that this estimate may be overly conservative, putting that number two or three times higher. Resilient industrial networks help prevent downtime and its ensuing expenses by restoring network functions when they go down.
A resilient network infrastructure strives for 99.999% uptime in its operations, also known as the “five nines” of network availability. This translates into about six minutes of downtime per year. Only a highly resilient network infrastructure can meet such demands, ensuring network availability throughout an entire network.
Network Redundancy
In discussing two types of networks and architecture, network redundancy and network resilience are frequently used interchangeably. However, network redundancy is just one dimension of network resiliency, a part of the so-called “four Rs” of network resilience: Redundancy, Robustness, Resourcefulness, and Rapidity.
Network redundancy is a strategy of having a duplicate in place in the form of redundant physical or virtual hardware or interconnections. In the event a device or connection goes down, another simply picks up its job and normal network operation resumes. Without a backup disaster recovery plan or effective layer 2 redundancy, you’ll face an uphill climb to get systems back up and running.
A commonly cited example is a redundant firewall featuring an active and a standby mode. This configuration consists of a primary and secondary unit. The secondary unit sits idle in standby mode while monitoring the health status of the active primary unit. If it detects the active unit has failed, the secondary unit moves from standby to active. A variation of this configuration is to have both firewalls set to active modes, equally sharing responsibilities for routing and security policy enforcement. If one fails, the other seamlessly takes over its duties along with performing its own.
Industrial Ethernet Switching Redundancy Protocols
This brings us to industrial Ethernet switching network redundancy. This type of redundancy refers to the ability of a redundant network to survive a failure in its switch-to-switch links by providing an alternative data path.
Star Topology
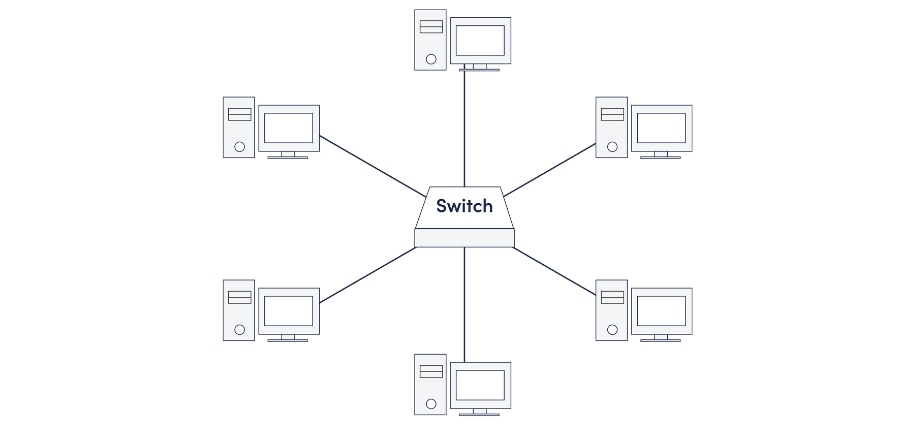
To illustrate this point, let’s look at a basic star topology. If one device in a star network wants to send data to another device, it first sends the info to the connecting network device (network switch) at the center of the star that then transmits the data to the designated device.
The obvious disadvantage of providing multiple paths, is if the network switch at the center fails, all nodes attached are disabled and users at multiple data centers can’t participate in network communication. In fact, a consequence of single path designs is that any hardware, or power outage, or cable failure will interrupt all types of network communications.
Figure 1: Star network with switch at center
To get around these limitations and improve redundancy, network administrators can add segments or additional industrial switches or use another type of topology altogether, such as mesh, link aggregation and redundant rings. However, whenever computers share information over a LAN with redundant pathways, looping issues can emerge and bring about broadcast storms.
Broadcast Storm
Broadcast frames have been known to be taken down by flooding the network with bogus frames preventing important frames from getting on the network or reaching their destination. Two major sources (but not the only) of these types of frames come from either malicious denial of service attacks or failing Ethernet devices. There has been fewer of the latter in recent years as Ethernet device quality has improved. A bad configuration might also cause this issue. Normally, a broadcast frame is passed through a switch to all ports. It is a broadcast like the name says and goes to everyone. However, a switch with Broadcast Storm Protection turned on will see too many broadcast frames and squelch them down, preventing them from propagating throughout the network. Once the stream of broadcast has subsided, the switch will permit the traffic to pass once again. It resets itself. Typically, this is turned on by default in most switches. It is possible some applications might require this to be turned off due to traffic being intentionally broadcast traffic, but is very rare.
Spanning Tree Protocols
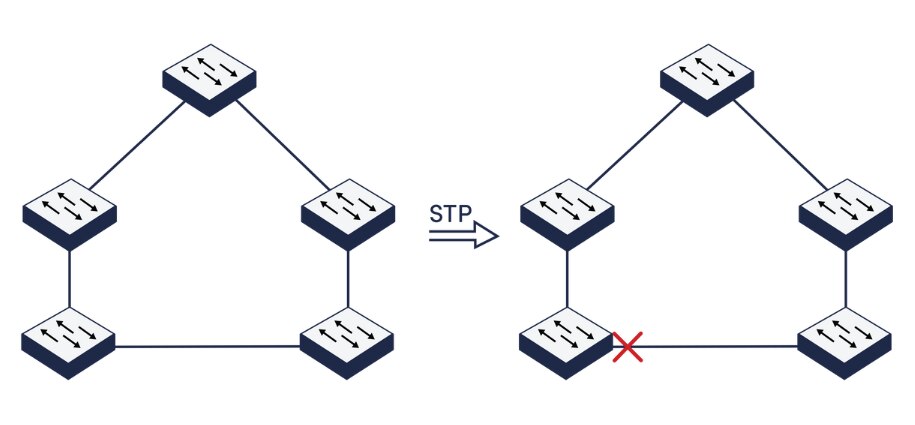
To break looping cycles and avoid broadcast storms, network administrators have long implemented Spanning Tree Protocol (STP), a popular layer 2 protocol. STP prevents the occurrence of network loops by blocking all redundant networks' ports. In a loop-free network a single device with a blocked port will still receive data but it will not send that data out to other devices on the network. STP disables links that are not a part of the spanning tree, leaving just one primary path and one active channel between any two network nodes. When a network failure does occur, however, devices are able to continue communicating across the network since data can be rerouted around the failure. The port that is selected depends on the topology of the configuration.
Spanning Tree (STP, RSTP, MSTP)
There are three versions of the STP protocol: STP (802.1d), Rapid STP (RSTP, 802.1w), and Multiple STP (MSTP, 802.1s). The main advantage to RSTP over STP is its reduction in convergence time. When there is a topological change, RSTP can usually react in a matter of 5-10 seconds, whereas STP can take up to 50 seconds. MSTP is the application of STP to a virtual LAN (VLAN). MSTP maps a group of VLANs into a single Multiple Spanning Tree instance, resulting in improved network performance and stability by ensuring that only one active path exists between any two nodes in an MST instance. A switched network is divided into multiple regions by MSTP, and each region has multiple independent spanning trees. MSTP not only facilitates rapid network convergence but also lets the data flows from different VLANs be routed separately.
Figure 2: Network devices showing Spanning Tree Protocol
Ethernet networks must not have loops. Spanning Tree protocols prevent loops by disabling one of the connections. If one of the working connections should fail, Spanning Tree will enable the originally disabled link providing connectivity once again. RSTP (Rapid Spanning Tree Protocol) differs from STP (Spanning Tree Protocol) by using faster algorithms to block and unblock the links. MSTP (Multi Spanning Tree Protocol) works on VLAN connections rather than physical interface connections which allows it to block data from a single VLAN that has created a loop while allowing other VLANs, which are not looped, to continue to use the link.
Other Resilience Strategies and Protocols
Besides STP, RSTP and MSTP, there are several other resilience protocols and technologies. Three worth noting are Ethernet Ring Protection Switching (ERPS), link aggregation, and Virtual Router Redundancy Protocol (VRRP).
Ethernet Ring Protection Switching (ERPS)
Initially developed for carrier and metro networks, ERPS uses the ITU-T G.8032 standard to create a ring of nodes configured to prevent loop issues. While nodes are arranged in a ring, one connection is always blocked to prevent the creation of a loop. This way traffic can flow in both directions around the ring but always stops at the blocked link. If another link in the ring goes down, however, it becomes the blocked link and the previously blocked link is opened, allowing data flow to continue at the same rate with virtually no loss of speed. ERPS rings can also be connected in multiple layers to create larger stacks. Even over hundreds of miles of fiber connections, the protected ring structure of ERPS means that ping won't drop, and connections will remain stable. Several Antaira industrial managed switches support the ring network redundancy function using the open standard ITU-T G.8032 Ethernet Ring Protection Switch (ERPS) protocol that has a less than 50ms network recovery time. If you are building out a new network redundancy and framework that prioritizes rapid recovery, ERPS may be the best choice.
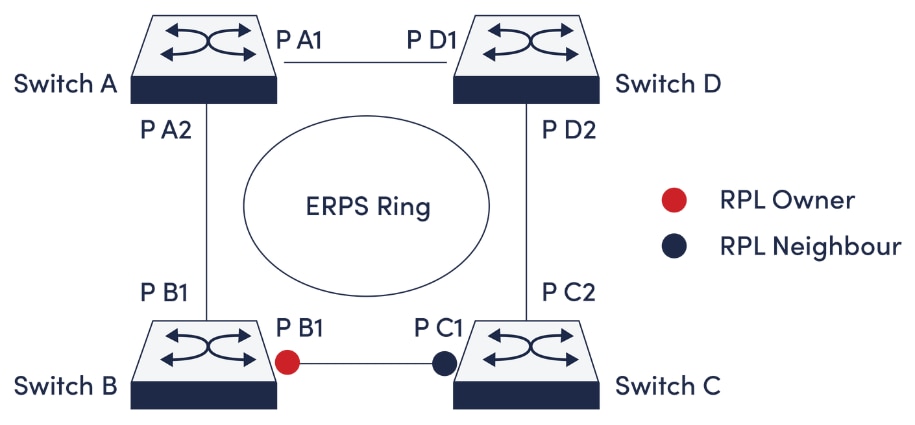
Figure 3: ERPS ring
Again, Ethernet networks MUST not have loops. ERPS, like STP, disables a link to remove the loop from the network. Like the Spanning Tree protocols, if a working link should fail, the previously disabled link will be re-enabled creating a more resilient network. While STP can be used in a network that looks like a mesh, disabling multiple links to prevent loops, ERPS can only be implemented in a loop. By limiting the design to a loop, ERPS can provide faster healing times (sub 50ms) to the network.
Link Aggregation
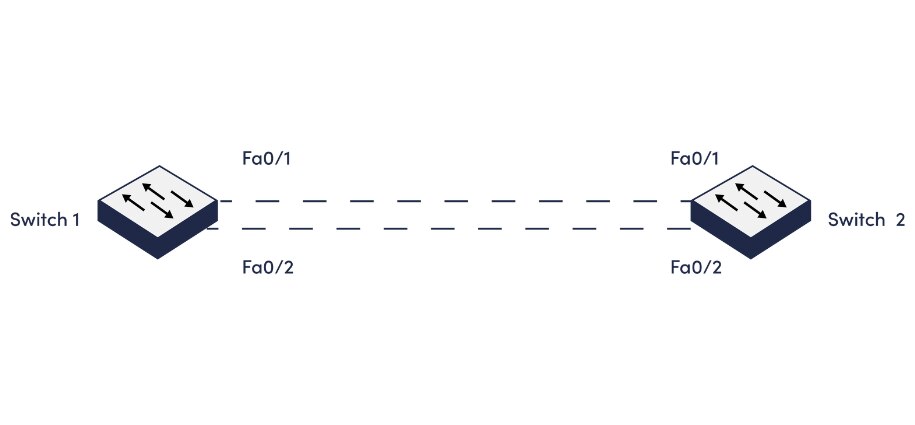
Link aggregation bundles multiple individual Ethernet links together from two or more devices, so the links act as a single logical link. This can be done without having to use STP to disable a redundant link. Connecting a switch to another switch, a server, a network attached storage device, or a multi-port access point are the most typical device combinations. Besides optimizing load balancing, an important reason for using link aggregation is to provide fast and transparent recovery. An aggregate set of ports is referred to as a link aggregation group, or LAG, and each of these links must be the same type of Ethernet (10/200/1000/10G, et cetera) and configured identically. The physical links operate in an active-active or active-backup setup, meaning that if one physical link fails, the other can take over and restore the traffic forwarding previously sent over the failed link.
Figure 4: Link aggregation
LACP (Link Aggregation Configuration Protocol) is a point-to-point protocol that creates redundancy and increased bandwidth between devices, typically industrial switches. In the above example, a loop is created by connecting two Ethernet switches together with two links. LACP prevents issues by creating one logical link out of the two links and eliminates the issues caused by a loop. Both links are capable of transmitting different data at the same time thus doubling the bandwidth. If one link fails the other can still carry data. Up to 8 links can be bound together to form a single LACP connection.
Virtual Router Redundancy Protocol
Virtual Router Redundancy Protocol (VRRP) is an open standard protocol that enhances network reliability by providing router redundancy for network services. VRRP does this by using physical hardware and creating a virtual router made up of several physical routers. When packets are delivered to the virtual router from one server's IP address, the industrial router with the highest priority acts as the master. The group's other routers stay in standby mode, prepared to take over if the master router malfunctions.
Conclusion
In today's industrial markets, network downtime is no longer tolerated. To improve your network’s resiliency, Antaira has a wide range of cost-effective, open source switching solutions in multiple configurations. Our industrial managed switches support RSTP, MSTP and ring network redundancy using the open standard ITU-T G.8032 ERPS, giving you more options for peak performance no matter where, how, and when you connect. Plus, when you call Antaira, you will talk directly to a member of our engineering team. They will help you to gain a better understanding of how network redundancy works, and how it can be best deployed depending on your application, budget, and current framework.